A Ruby Design Process - Talking Points
At RubyConf 2012, I gave a talk proposing a Ruby design process. Following the conference, I detailed the process in a blog post. I submitted a ticket on the MRI bug tracker asking Matz to consider my proposal. The proposed design process is summarized on the RubySpec website. If you support the proposed process, please add your voice by signing at the above link.
The discussion of a Ruby design process is emotionally charged. People focus on their own ideas and illusions far more than facts. Conversations resemble political debates, not technical discussions. Consequently, ten times more energy is invested in clarifying misunderstandings and misinformation than in substantive discussions about the merits of the proposal.
To help keep the discussion focused on the merits, the following points amplify and further explain the proposal.
Priorities
Every reasonably complex endeavor has elements that compete. Examples are all around us. "You can have it fast, cheap, good; pick any two." The CAP theorem. Enough time for recreation but enough money to pay the bills. The only way to resolve such tensions is to prioritize. The same is true of a Ruby design process.
The Ruby programming language is complex. Any implementation of the language is unavoidably complex. There are half a dozen significant implementations of Ruby. Those all represent different interests in Ruby. Attempting to implement a unified definition of Ruby is undeniably complex and difficult.
It's easy to imagine that Matz would have different priorities than another team implementing Ruby. The purpose of the proposed design process is to prioritize those things that create a unified Ruby programming language.
For businesses and developers whose salaries derive from writing Ruby, the value of a unified Ruby programming language should be obvious. If someone believes that businesses, customers, and developer salaries would be better served by a fragmented Ruby language, they are encouraged to give their argument in support of it.
There is no definition of the Ruby programming language that is complete and accurate enough to provide unity to the Ruby community.
The proposed Ruby design process prioritizes the following things:
- A precise and clear description of what exactly is the Ruby programming language.
- Efficient use of the time and attention of implementers.
- Fairness to all implementations in deciding Ruby programming language features.
The Design Process Is Focused On The Definition Of Ruby
The product of the proposed design process is a precise, verifiable, and unified definition of the Ruby programming language. The definition is independent of any particular implementation. There are numerous programming languages used to implement Ruby. None of those languages, or implementation artifacts that result from the use of those languages, should be given special preference in the definition of Ruby semantics.
The RubySpec project is the only project that has the explicit goal of a complete, executable description of the Ruby programming language. The product of the proposed design process is a more complete and more accurate RubySpec exactly describing the behavior of the Ruby language in a way that gives developers and the rest of the Ruby community clarity and confidence in understanding Ruby.
The Design Process Is As Simple As Possible, But No Simpler
The proposed design process does not impose any restriction on any implementation with respect to experimenting with Ruby language features. This appears to be one of the most misunderstood parts of the proposal.
Every implementation is completely free to experiment with language features. They can use whatever development model they choose, whatever source control they like, write or not write tests in any framework they fancy. They may collaborate with other implementations in any way they wish. They can discuss features in any language, on any mailing list they choose, or by means of any medium they wish.
In other words, the MRI developers can continue doing exactly what they have been doing.
The design process is only concerned with what becomes the official definition of Ruby. Experimental features may or may not ultimately have value. The design process is optimized for reaching consensus on the features that will be part of a unified definition of Ruby with the least amount of work or ceremony.
The Design Process Is Open To The Community
Right now there is no formal design process for determining what features are officially Ruby. There has never been a design process. People sometimes propose a feature to Matz and sometimes he accepts it. Most of the time, language features result from Matz's experimentation with the language. Matz has repeatedly said he has the absolute authority to decide what features can be called Ruby. If this ad hoc process is "open" to the community, then so is the proposed design process.
Under the proposed design process, anyone, whether from the Ruby community or not, can propose a feature to Matz, just like they can now. If Matz agrees with the proposed feature he, or other MRI developers, can bring it to the Ruby design council for discussion and approval. Hence, the proposed process is just as "open" to the community.
However, the proposed process is even more open to the actual Ruby community. There are Ruby developers that are entering the community from Java and may never use MRI at all. If they have an idea for a Ruby feature, they may be able to implement it in Java but not C. They would be able to work with JRuby to propose a feature that has been implemented, tested, and validated with actual experience.
The Design Process Is Efficient
The proposed design process requires that language experiments are clearly documented and described by precise specs before being proposed as official Ruby features. The discussion then focuses on concrete issues. This approach makes efficient use of the attention of Ruby implementers. It also limits communication about irrelevant details, further reducing the burden on Ruby implementers when reviewing proposals.
Most important, precise specs makes the effort of implementing the feature as small as possible. This also makes the most sense: Who is more qualified to describe precisely how a feature works by writing specs but the people proposing the feature?
While the design process requires documentation and RubySpecs, it does not prevent an implementation from writing fully functional code for the feature. The design process only lists what is required in a proposal. It's doubtful any feature could be proposed with sufficiently detailed documentation and RubySpecs without any code.
The Design Process Concerns Language Evolution, Not Experimentation
Under the proposed process, Matz is as free to experiment with the Ruby language as he ever has been. So is every other Ruby implementation. However, developers, businesses, and Ruby implementers get clarity, visibility, and transparency for what is officially Ruby. The proposed process is only concerned with features that will be part of the unified definition of the Ruby language.
The proposed design process is not concerned with how implementations experiment with language features, with what VCS they use, or what bug tracking software, whether they practice BDD/TDD or write tests at all, what language they use while discussing Ruby over lunch, or any of a myriad other activities not explicitly defined by the process.
English Is A Reasonable Language For Collaboration
The proposed design process attempts to reduce as much as possible the need for all implementers to discuss proposed language features. The discussion occurs after clear documentation is written, after precise RubySpecs are written, and after everyone implements the feature so that it passes RubySpec. The discussions then focus on concrete facts about the impact of the proposed feature to existing and future code, whether it is in libraries, frameworks, or applications.
For the limited discussion that is required, English is a reasonable language. It is the only language that is likely to be used to some extent by all the Ruby implementations. It is the language used by international communities in computing, science, mathematics, and other fields.
In fact, English is the language in which the Ruby ISO standard is written. And that standard was written by MRI Japanese developers.
The Design Process is Fair
Matz and other MRI developers have put a tremendous amount of effort into the Ruby language. However, so have all the developers of other implementations of Ruby. In fact, the combined effort on other implementations of Ruby very likely far exceeds all the effort dedicated to MRI. Every implementation of Ruby is helping Ruby and helping Ruby developers.
Most importantly, other implementations of Ruby are helping Ruby developers in ways that MRI and Matz are not. Furthermore, while Matz may know a lot about Ruby, he doesn't know everything about the many challenges Ruby faces. Matz is not a concurrency guy, or a business guy. He's said that himself. He's also not likely a Java guy, or C# guy, or crypto guy.
The Ruby language needs a design process that fairly distributes authority over what features become officially Ruby. There is no process more fair than consensus among all the Ruby implementations. These are people who have dedicated tremendous effort to understand and implement the many complex idiosyncratic Ruby behaviors and support developers in many difficult environments.
If all the implementations believe that a feature is bad for Ruby, Matz should not ignore their collective wisdom and dedication to Ruby. The proposed design process merely formalizes that fact. Finally, if Matz disagrees, he is still free to include the feature in MRI and demonstrate its importance. The same is true of every other Ruby implementation.
A Design Process Is Critical At This Stage Of Ruby's Development
At this stage of Ruby's development, a design process is critical. Point out a single other widely used programming language with a half-dozen implementations with a unified definition of the language and no formal process for agreeing on that definition.
Ruby has no formal design process, despite Ruby being an industrial strength programming language, having hundreds of millions of dollars invested in businesses built around the language. There is no process to maintain unity of the Ruby language. There is no definitive resource defining Ruby. Developers can only support multiple Ruby implementations with trial and error.
It is short-sighted and irresponsible to advocate for the ease of experimenting with random language features over the stability and unity of the Ruby language. Ruby is not a toy language. It is almost twenty years old. It powers many businesses and pays tens of thousands of developer salaries.
Matz created the language. His creation has been a gift to the world. The Ruby community has been and continues to be immensely grateful to Matz and deferential to his opinions and there is every reason to believe that will continue. Insisting that one's ownership of a language is paramount at this stage of its development is unreasonable.
The proposed design process seeks to create these three things:
- A definition of the Ruby language that is independent of any particular implementation of Ruby.
- A definition of Ruby that is explicit and verifiable by running RubySpec.
- A process of deciding what features are in the Ruby language that is fair to all implementations of Ruby.
If you disagree with those goals, please explain why the goals are not good for Ruby. If you believe the proposed process would not promote those goals, please explain why.
If you support the proposed process, please talk to people about it and why you support it. Also, please add your voice in support.
A Ruby Design Process
Ed: Since the initial post, I have fixed some minor grammatical and spelling errors pointed out by Rich Morin.
Ed: If you support the proposed design process, please add your voice by signing here.
The Ruby programming language needs a design process.
I gave a talk on this topic at RubyConf 2012. While the talk presented reasons why we need a design process, I'm mostly focusing on my proposal in this post. On Monday, December 10, 2012, we had an IRC meeting of Ruby implementers. Most of the components of my proposal were discussed. However, I think a fair amount of misunderstanding remains. With this post, I hope to offer some clarification.
Setting a Stage
Once upon a time, a very long time ago, there was a single implementation of Ruby. Matz was the initial author and over time various people contributed to the project. We generally refer to this implementation as MRI or Matz's Ruby Implementation. Today, there are half dozen significant Ruby implementations. These cover major platforms from the JVM to a Smalltalk VM to Microsoft's DLR. Each of these platforms are quite different, having specific limitations and advantages.
Matz still works on MRI to some extent, which is now only one implementation out of many. Yet, for many people, MRI is still synonymous with Ruby. In other words, people generally assume that "the Ruby programming language" and whatever behavior MRI, the implementation, exhibits are one and the same thing. However, Ruby is an extremely complex language with many special cases, a big core library, and an even bigger standard library. For all the other implementations of Ruby to have consistent behavior, there must be a way to define what is Ruby.
We need a precise standard, or specification, for Ruby.
But wait, didn't I just say that we needed a design process for Ruby? Yes, I did. A design process is a means to create a precise standard for Ruby. But there is another reason that we need a design process for Ruby.
The world is constantly changing. As an industry, we have been reading and hearing about the need to deal with concurrency as CPUs get more cores and computers get more CPUs since the late 1980's (that's before a lot of programmers today were born). But it is now becoming an unavoidable reality. Discussions about concurrency in Ruby usually focus on the MRI global interpreter lock. Unfortunately, that specific limitation of MRI gets an unfair share of the attention. Concurrency and potential parallelism are much bigger topics and need attention. A memory model, thread semantics, concurrency primitives other than threads, and concurrent data structures are all topics that must be addressed.
We are also seeing a huge change in the way applications are built and deployed. Heterogeneous networks of services deployed in the cloud and interacting in unforeseen ways is the future. The future is not evenly distributed but it is already all around us. In this environment, security is a vital consideration. Further, an extension API for Ruby to integrate with libraries and applications written in numerous other languages is essential. Not everything can be turned into a service natively and writing a service layer may mean integrating a library or application written in another language.
The Great Benefits
It should be wildly uncontroversial that everyone in the Ruby community benefits from a specification for Ruby. What may be under-appreciated is who exactly we are referring to when we say the Ruby community. My definition is broad and includes people who use applications written in Ruby, businesses who use applications written in Ruby, businesses who pay people to write applications in Ruby, and people who are paid to write applications in Ruby.
Ruby is a mature, industrial-strength programming language. Hundreds of millions of dollars have been invested in Ruby, Ruby companies, and Ruby applications. Think about that for a moment. About six years ago, a few hundred Rubyists attended the first RailsConf. Many of them were not being paid to write Ruby or Rails applications yet. That's just six years ago. Today, it is hard to find a person attending a RubyConf or RailsConf or any of numerous regional Ruby conferences who is not paid to write Ruby. That is a huge number of families that depend on a salary that comes from writing Ruby code.
It is incumbent upon all of us who can make a difference to ensure that we give our best effort to make good decisions for Ruby. Decisions that further the quality, reliability, security, and usability of Ruby. Decisions that safeguard the well-being of people that depend on Ruby.
A Decent Proposal
The foremost goals for this proposed Ruby design process are 1) the quality of decisions made about Ruby, and 2) language unity.
I want this point to be as clear as possible. Ruby is a fantastic language. It does not need huge changes. What Ruby needs is stability, unity, and changes that address the challenges for using Ruby to create modern applications. Wherever this proposed process seems heavy, it has been designed to produce good decisions and limit Ruby changes.
Here is the proposed process:
- A Ruby Design Council made up of representatives from any significant Ruby implementation, where significant means able to run a base level of RubySpec (which is to be determined).
- A proposal for a Ruby change can be submitted by any member of the Ruby Design Council. If a member of the larger Ruby community wishes to submit a proposal, they must work with a member of the Council.
- The proposal must meet the following criteria:
- An explanation, written in English, of the change, what use cases or problems motivates the change, how existing libraries, frameworks, or applications may be affected.
- Complete documentation, written in English, describing all relevant aspects of the change, including documentation for any specific methods whose behavior changes or behavior of new methods that are added.
- RubySpecs that completely describe the behavior of the change.
- When the Council is presented with a proposal that meets the above criteria, any member can decide that the proposal fails to make a case that justifies the effort to implement the feature. Such veto must explain in depth why the proposed change is unsuitable for Ruby. The member submitting the proposal can address the deficiencies and resubmit.
- If a proposal is accepted for consideration, all Council members must implement the feature so that it passes the RubySpecs provided.
- Once all Council members have implemented the feature, the feature can be discussed in concrete terms. Any implementation, platform, or performance concerns can be addressed. Negative or positive impact on existing libraries, frameworks or applications can be clearly and precisely evaluated.
- Finally, a vote on the proposed change is taken. Each implementation gets one vote. Only changes that receive approval from all Council members become the definition of Ruby.
1. A Ruby Design Council
A council of people with many different and sometimes competing interests has been used at every level of government and organizations to ensure that different viewpoints are considered and reasonably good decisions are made.
A council is the only equitable way to ensure that the definition of Ruby fairly considers all the competing interests that exist. If the process is not equitable, it will not be respected. The unity of the Ruby language is something of tremendous value to the Ruby community.
2. Submitting a Proposal
I must emphasize that the proposal is not where the process of working on a Ruby feature begins.
Any implementation is free to experiment with Ruby changes in any way they choose and using whatever testing or coding style they select. They are free to discuss the process in any forum using any language they choose.
Writing code and playing with it is one of the main ways to get a feel for a feature. The design process proposed here does not intend to interfere with that. It is also expected that discussions and collaboration between different Council members would be undertaken long before a proposal is submitted.
Ruby is a very complex language. Changes to Ruby should not be considered lightly. Ruby is not a playground. It is a language that has a responsibility to a huge community.
Requiring that a proposed change be made by a Council member ensures that poorly fitting changes are not added to Ruby. At the same time, any change that has a clear and significant benefit deserves the effort to be presented in a way that ensures it will be understood by the Council members and taken seriously.
3. Criteria for a Proposal
Proposing a change to Ruby is not a trivial undertaking. It should be deliberate and carefully thought out. It is not an unreasonable burden to require that a proposed change be completely understood by the member proposing it.
Writing documentation and RubySpecs is the best way to ensure that the proposed change is understood and can be communicated to the rest of the Council. Since the goal is the best decisions we can make for Ruby, setting a high expectation for a proposal is a benefit.
4. Proceeding with a Proposal
Any proposed change that has met these criteria has been carefully thought out and described. The specific details of behavior have been written down in a way that any implementation can implement.
However, that does not mean the proposal is a good idea for any number of possible reasons. As an initial sanity check, all Council members must decide whether the effort to implement the feature is justified. This barrier should be viewed as an additional guarantee that changes to Ruby will be adequately understood and carefully selected for the benefit of the Ruby community.
5. Implementing a Proposal
Every Council member must implement a proposal that passes the initial evaluation. The RubySpecs provided in the proposal will guide and clarify the implementation.
Confronting the platform and system constraints while implementing the feature ensure that it is completely understood. Likewise, having a complete and working implementation is the best way to limit unintended consequences and understand as much as possible how existing code will be affected by the new feature.
6. Discussing the Implementation
Once the proposal has been implemented by all Council members, the time is ripe for discussion. It is only with the concrete reality of how the feature performs and interacts with the rest of Ruby that good decisions can be made.
The express intent of all Council members is to implement a unified definition of Ruby. If the feature is going to be Ruby, it is going to be implemented by all members. It presents no burden to require that the implementation precede the discussion. If, after implementation, the feature fails to meet the needs that motivated it, everyone can be satisfied that the best possible evaluation was given. If unforeseen implementation issues are discovered, the feature can be revised and resubmitted.
7. Voting on a Proposal
Just as a council is the equitable way to share responsibility and decisions about Ruby, so it must be that every Council member's vote has equal validity. It is true that every Council member holds veto power. But that should be seen as a strength of the process, not as a liability.
Matz still has the ability to say what features become officially Ruby. He can exercise his vote to not approve any feature. However, the rest of the Council could also vote not to approve a feature that Matz wanted. If this causes the slightest bit of fear for the well-being of Ruby, please allow me to dispel it.
First of all, the Council is made up of people who have spent years implementing Ruby. Many of those people spend some of their time as unpaid volunteers. Every one of those people up to now has committed tremendous effort to create a compatible implementation of Ruby even when no actual specification existed.
Furthermore, people like Charles Nutter have gone to tremendous lengths to implement features like POSIX-compatible behavior on top of the JVM so that Ruby compatibility would be respected. That level of dedication must be respected and applauded, not feared. We have all put the well-being of Ruby first, and if we truly feel that a feature would cause harm to Ruby, we should be allowed to prevent it from being included in the definition of Ruby.
In practice, I have absolutely no reservation about giving veto power to any member of the Ruby Design Council.
What Really Changes?
By formalizing a design process for Ruby, what really changes about how we do our work?
Nothing in this proposal prevents any implementation, including MRI, from experimenting with Ruby features. Any, or all, of the Council members could collaborate on a proposed change to Ruby. An experiment for a new feature could be used by a portion of the Ruby community for a significant period of time before being formally included in Ruby. Any implementation is free to discuss a feature in their own way and with their own preferred version control system, bug tracker, testing methodology, means of communication and language.
Technology for Change
Finally, the question of what technology to use for submitting, discussing, tracking, and voting on proposals must be addressed.
Email is not sufficient and neither is a bug tracker. We need an application that allows commenting on each sub-section of a proposal, referencing multiple previous comments in a comment, viewing comments by proposal or by sub-section, tracking changes to a proposal, tracking references to RubySpecs and implementation code, and recording votes. The contents of proposals should be searchable and indexable. The process of deciding on proposals should be secure and audit-able.
I will create a specific application for this purpose and host it at design.rubyspec.org. Ruby deserves a sufficiently powerful tool to support making good decisions for the language.
Conclusion
Ruby needs a design process. The process described here focuses on language unity and making good decisions for the Ruby community. The process gives maximum liberty to all implementations of Ruby to experiment with new features while giving maximum clarity and support for the Ruby Design Council members to decide which proposed Ruby changes to accept.
We can choose to make the Ruby design process as efficient and effective as we wish. The intention should be collaboration and unity. Ruby, and especially the Ruby community, deserve our best effort.
Is Node.js Better?
NOTE: This is essentially a transcript of (though mostly written before) my JSConf 2012 talk, "Is Node.js better?". It's long, I know. There is no tl;dr, sorry.
Is this better than that?
This is a question that we confront constantly. Numerous times a day, in fact. And sometimes a lot rides on the answer. Is this job offer better than that one? Is this car better than that one? Is this home for my ailing mother better than that one? Is this billing system better than that one? Is this tax plan better than that one?
This question is everywhere. We cannot escape it. Yet for the frequency with which we confront it, our approach to resolving the question is quite likely not objective. Which is to say, we are probably not answering the question in a way that is mostly likely to benefit us. Many used car sales, software system sales, and political campaigns, to mention a few things, profit from our incompetence answering this question. We'll consider some of the reasons why that is true later. But just recognizing this is rather distressing.
But we're not just asking, "is this better than that?" in general; we're here at JSConf and this talk is about Node.js. Why? You probably know that I'm not a notable member of the Javascript community. I have not authored a single JS library. I've never given a talk at a JSConf. Why am I here? And why am I talking about Node.js?
I met Chris Williams at CodeConf 2011, organized by Github. Chris sat down next to me during the Node.js talk by Ryan Dahl. I found the talk fascinating because much of it focused on improving the non-blocking I/O facilities in V8 for both Windows and Unix-ish platforms. This was something that we have a lot of interest in for the Rubinius project and I had then recently started porting Rubinius to Windows.
At the time, I had no idea who Chris was. But we chatted a bit and at the break, Chris stood up and said, "I'm going to get some more beer, would you like some?" Holy shit. That's why I had been smelling beer for the last 45 minutes! Chris had a coffee cup full of beer. Hilarious. One person's moderation is another person's excess.
I declined the beer then but we exchanged contact info and Chris put me in touch with folks from Microsoft who were assisting with getting Node.js running well on Windows. Chris also informed me of the upcoming JSConf that was being held in Portland, where I live. It was too late to get tickets but I was able to attend the opening party and made a point to hang out as much as I could with the other attendees at conference events. At the time of CodeConf, I was merely curious about Node.js, but I didn't have much of an opinion.
Fast-forward almost nine months. I was seeing a flurry of tweets about Node.js. This got my attention, in part because of the people who where tweeting about it. I use Twitter as one of my main sources of information about developing technology. The more tweets I saw, the more uneasy I felt. Finally, one morning I posted this:
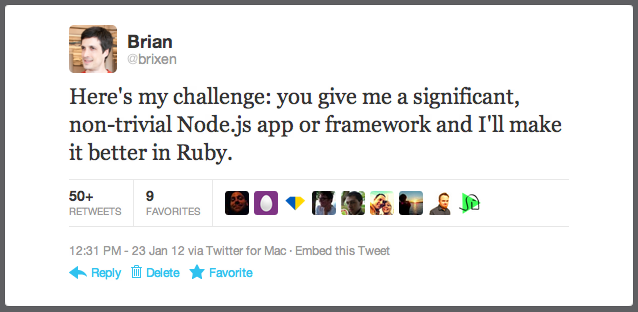
My intent was not to be antagonistic. Rather, my challenge was focused on finding out what sort of problems people were solving with Node.js. But any challenge, even a sincere one, carries a connotation of aggressiveness. And it is a fact of human nature that when pushed, people tend to push back. Some of the responses to my tweet attempted to share knowledge but others were understandably of the genre, "if you're looking for a fight, you'll find one here."
It wasn't long before Chris DM'd me and basically said, "What's up with this 'challenge'? You are working on important stuff, why are you wasting time on this?" I answered that I was genuinely interested in understanding why people are using Node.js. We exchanged a few comments over a several days and Chris asked if I was willing to do a talk on the subject. So that is how I got here, talking about Node.js at JSConf. It is a honor and privilege to be here and I thank Chris and the conference organizers, as well as all of you.
So who am I? I've been working on the Rubinius project for the past five years, and four of those while employed full-time by Engine Yard. I started the RubySpec project as part of my work on Rubinius. Through my work on Rubinius, I have learned a lot about compilers, virtual machines, garbage collectors, and importantly, concurrency. One of the notable points about Rubinius is we have removed the global interpreter lock (GIL) so that multiple native threads can run Ruby code in parallel on multi-core or multi-CPU hardware. We see this ability as vital to the success of Rubinius.
Now that you know how I came to be speaking at JSConf and you know a little about what I do, the question remains, "Why am I speaking at JSConf? Why do I care about Node.js?" The answer to that will take us on a journey through some interesting territory. I only ask that you suspend prejudice and follow along. If you ultimately disagree with me, there is nothing wrong with that.
Organizations tend to perpetuate the problem they were created to solve.
I don't remember exactly when I was introduced to this idea, but it had a significant effect on me. There are a lot of difficult problems to solve in the world and one of the first things we tend to do is create an organization that is dedicated to some aspect or another of a solution. Notice that there is a difference between people organizing to solve a problem and an organization. As soon as we have an organization, it will tend to take actions to perpetuate itself. Of course, these actions are really the decisions of people in the organization. The organization has no effective power independent of the people who comprise it, yet the organization as a whole is a system, and will tend to exhibit life-preserving actions. If an organization exists to solve a problem, and that problem is solved, the organization ceases to have a reason to exist.
Every time we organize for any reason, there is a tendency for structures to solidify. The rigidity of those structures tend to inhibit movement and change as circumstances change. Therefore, a vital force in social organization is the force that opposes established order. There is a name for this force: subversive, something seeking or intending to subvert an established system or institution. People who participate in subversive activities are called subversives.
There is another aspect to this that is important. People tend to be in one of two groups: those who fear change and those who create change. When we think of "change", it usually has a positive connotation, and "subversive" has a negative connotation. But they are often the same thing. Change can be positive or negative. But as it has been said, "there is only one constant: change."
Javascript has been an amazing technology wielded by people who have radically and fundamentally changed how we interact on the web. This is fascinating and tremendously valuable for societies all over the world. So part of the reason why I'm speaking here is that people enthusiastic about Javascript are people who are creating change. I want to acknowledge, assist, encourage, collaborate with, and influence people who are actively working to change the world for the better.
This talk is about conflict resolution. Conflict is inherent in the question, "Is this better than that?"
It's important to note that any contrast implies conflict. Sometimes people assert that you should be able to promote something without saying anything bad about something else. This idea is impossible to comprehend. If I say, "water is good," it is inherent, even when implicit, that I'm saying water has value and value is a concept that relies on a context and a standard. There is no concept of value that is not relational. Something is only good relative to what you are judging it against.
Criticism is advocacy; advocacy is criticism. Criticism is also controversy and controversy is entertaining. However, despite the entertainment value, different ways of resolving conflict can have very negative consequences. Usually when there is conflict, we address it with aggression. We talk about having a "shootout", "fight", "throw down", etc. But are fights a healthy, beneficial way to resolve controversy?
Further, when a person comes out as a strong advocate for some technology, people opposed to the technology will hurl the epithet "fanboi" as an attempt to discredit the idea by attacking the person. From the other direction, if we don't like someone's criticism, we may call the person a "troll".
Other times, we will simply attempt to avoid conflict entirely. In Ruby, there is this idea, MINASWAN: Matz is nice and so we are nice. There is nothing wrong with being nice, but why is "nice" contrasted with "criticism"? Are we supposed to never challenge someone because being "nice" is more important and challenging them is inherently not nice? What if someone is doing something that from our experience is not beneficial to themselves or others?
For the most part, this is how I see us dealing with conflict. We either avoid it or we attempt to devalue the person rather than discuss the idea. This is dysfunctional. Basically, we suck at conflict.
How can we improve how we deal with conflict?
I assert that we need to use science. But how? What does that mean? To understand this, we need to look more deeply at how we as humans think. But before we get to that, let's consider a very common aspect of social organization: the tendency to surrender our own judgment to that of an "expert".
In 1948, Alex Osborn, who was an ad man at B.B.D.O., wrote a book, Your Creative Power, where he introduced "brainstorming". Essentially, a group of people toss out solutions to a problem under consideration. The emphasis is on generating as many ideas as possible. A key element of the activity is that everyone is told not to criticize their own or other's ideas. It was asserted that creativity was too delicate a process to withstand the harsh light of a critical challenge.
Of course, that made a lot of sense to people. Over the years, brainstorming has been used extensively in problem solving. It is still heavily used. The problem is, the method is flawed. The proscription against criticism happens to be wrong.
There were two studies that tested the two main components of the brainstorming methodology for discovering creative solutions. The first focused on individuals versus groups. The result was that people working alone produced not just more but better ideas than the groups.
The second study focused on the suspension of criticism. The subjects were divided into three groups. The first group were instructed to use brainstorming and told not to criticize their own or each other's ideas. The second group were instructed to challenge and debate one another. The last group was allowed to organize themselves without any instruction in a particular method. The results from this experiment were unambiguous. The debaters significantly outscored both other groups. The act of criticizing other's ideas causes both the questioner to understand the idea more fully and the person proposing the idea to go more deeply into it.
The important lesson is two-fold. Criticism is an important aspect of creative, intellectual effort. Despite the proscription against criticism having superficial validity, it was rather easily disproved.
Another interesting study related to creativity examined whether there was a correlation between the success of Broadway musicals and how well the team producing the musical knew each other. The measure of team familiarity was named the Q factor. A team where all the members had worked together before would have a high Q factor. A team where no members had worked together before would have a low Q factor. The study found that there was indeed a significant statistical correlation between Q factor and success of a musical. In other words, a certain range of Q factor was a good predictor of success. The value of Q that was most likely to predict success was from a team where most members had worked together previously but some members had not. A team where no one had worked together wasn't able to communicate effectively enough. A team where everyone had worked together didn't benefit from an outsider's perspective challenging ideas.
These results are reported in Groupthink: The Brainstorming Myth by Jonah Lehrer, published in New Yorker magazine, January 30th, 2012. The lesson we can take is that criticism is important to creative solutions to problems and we should be seeking people who are unfamiliar with our favorite language or framework to join us and help our understanding of problems and the solutions we are building.
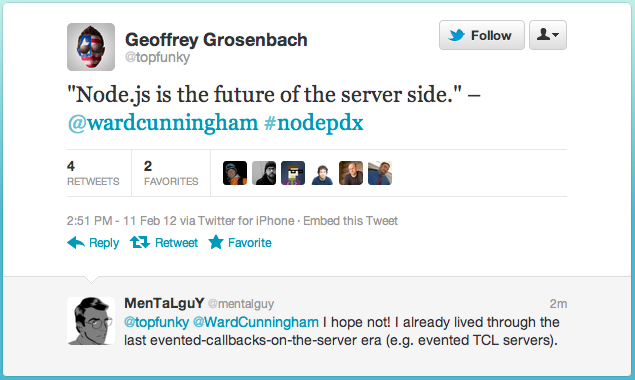
Another lesson is that there is nothing that prevents a well-meaning and experienced expert from being wrong. One thing that we should all be challenging is "appeals to authority" in decision making. As you can see from the following tweet, Ward Cunningham thinks Node.js is the future of the server side. However, that assertion is most likely not taken by readers of the tweet as a neutral assertion of fact about Ward's opinion. It is taken as meaningful because Ward said it. Further, it is unremarkable that the assertion is unaccompanied by any evidence with which to help determine the validity of the assertion. Assertions by experts with no accompanying evidence are the status quo in our industry, and that should be extremely embarrassing.
The next part of our journey takes us to one of the most interesting books I have read. Thinking Fast and Slow by Daniel Kahneman (Farrar, Straus and Giroux, 2011) is a book about how our minds work. There are basically two modes that have distinct and surprising features in the way we think. These two modes influence one another.
One mode is called fast thinking because our brains activate an entire network of associations in a sub-second burst of activity. For example, if I display the word "bacon", you will immediately have numerous memories and associations with bacon coming into awareness. This fast mode is all about pattern matching and the associations activated can be extensive and surprising. In this mode, the brain over-achieves, if you will. It activates far more associations than may be needed. And some associations may be surprising. It is up to the second mode to use those associations depending on the task we are confronted with.
The other mode is called slow thinking and is related to such activities as concentration, judgment, monitoring, and selecting. If I ask, "what is 23 x 47?" Answering this requires deliberate application of a set of tasks to arrive at the answer, unless the problem is one we are quite familiar with, in which case the fast thinking would just produce the answer as an association.
The book is filled with fascinating knowledge about how our thinking works and I cannot recommend it highly enough. It discusses numerous ways in which our thinking can produce erroneous beliefs and ideas. One of the very interesting results is that our deliberate, slow thinking can be easily fooled into accepting a wrong answer provided by our fast thinking mode if we feel at ease. But if we feel anxious, our slow thinking mode will be more critical and less likely to just accept an answer provided by our fast thinking mode.
Reading Thinking Fast and Slow and reflecting on the complex and inter-related behaviors that scientists have been able to discover facts about led me to the following conclusion:
Programming is a behavioral science.
Behavioral science is a very broad category that encompasses disciplines that explore the activities and interactions among organisms through systematic analysis and investigation using controlled observation and scientific experimentation.
There is a distinction between programming and computer science. Writing software is an activity that is mostly centered on human behaviors. Most software will interact with people at some point. Basically, it is written by people, for people, and funded by people. Of course, there are mathematical foundations of computing and algorithms, but those are rarely the most important elements of the process of creating software.
If you are familiar with the many methodologies under the "Agile" umbrella, you know that dealing with changing requirements is one of the most complex aspects of software construction. But note that those changes are almost entirely due to human behaviors. If we build a bridge, an environmental study will determine most of the forces that the bridge design must account for. Further, the laws of physics are quite well established. Engineering the bridge is not a terribly complex activity. However, in software, there is not a good way to clearly establish the constraints for the system we are building. People are responsible for most of the complexity in programming. That is why I assert it is a behavioral science.
What is curious to me is that a typical undergrad psychology student will likely have more exposure to research methods than a typical computer science undergrad or even graduate student. Research methods are activities directed at determining the validity of assertions. They are what enable us to separate knowledge from opinion. Fundamentally, they are related to two aspects of existence: the nature of the world (meta-physics) and the theory of knowledge (epistemology). To learn more about this, I would recommend Research Methods: the basics by Nicholas Walliman (Routledge 2011).
Turning from this general information about applying science to thinking and learning about research methods, let's look at Node.js again. One of the major assertions about Node.js is that it permits writing efficient web servers that must deal with many concurrent connections. So, let's look at some basic features of concurrency, including a possible definition of concurrency.
People are selfish, lazy, and easily bored.
I say that without any moral judgment. I think these are all biologically desirable features of organisms. We are selfish because we are responsible for our own well-being. We are lazy so we don't waste precious and costly-to-obtain energy. We are easily bored because we must constantly incorporate new material to maintain our existence. Of course, each of these attributes has an opposite and any individual will exhibit a combination of these behaviors. But these three attributes are interesting to consider in this context.
Scarcity is a fact of life. Infinity is a mathematical fantasy. There are a finite number of computers.
Combine scarcity with the attributes above about people and we have a reason for concurrency in computation.
When a single CPU with a single core is running, it can basically execute one instruction at a time. Of course, this is a simplification, but it is basically true. If we consider a program to be a sequence of instructions, I1..In, every possible ordering of those instructions is a plausible definition of concurrency. For example, a four instruction program could be I1, I2, I3, I4 or I3, I1, I2, I4, etc. Not all orderings are going to be meaningful given the semantics we expect from the program.
Now, consider that the program would be 100% efficient if all the instructions are dedicated to solving the problem for which the program exists. However, if any instructions are dedicated to changing the order of instructions, those would reduce the efficiency of the program by doing work that is not directly related to solving the problem.
Once upon a time, computers solved problems one at a time. The jobs were processed from start to finish one at a time. This is great for efficiency but not great for people. People don't want to wait for everyone else's job to finish before theirs. Nor are they willing to do a lot of extra work to make the computer most efficient. So the idea of time-sharing systems was born. Essentially, everyone got a little slice of time to use the CPU. Even though some efficiency was lost, and so everyone's program would ultimately take longer to complete, the average time to wait went from hours (a whole day, perhaps) to possibly a few minutes. Computers became interactive.
There are only a few mechanisms to re-order the instructions of a sequential program. (Note that we can generalize from the instructions of a single program to the instructions of a set of programs concatenated together. The fundamental considerations do not change.) One way would be to do a little work and then voluntarily yield control of the CPU to another program. At some later time, another program would yield control back to us. This would implement cooperative multitasking. Another way would be for some sort of supervisor to allocate a short amount of time to each program in sequence. This would implement pre-emptive multitasking. Once your time-slice is over, you simply have to wait until everyone else gets a time-slice before you can run again. Yet another way would be to allow a program to run until it performed some action, like writing to the display or reading from the disk.
Each of these mechanisms for interleaving the instructions of a serial program may have different trade-offs, and consequently, different efficiencies. However, there is nothing inherent in any method that dictates it would be more efficient than any other. I consider this a very important point missing from almost every assertion about the uniqueness of Node.js. People are saying, and others are repeating, that Node.js enables solutions that are not possible with other programming languages and frameworks. This is absolutely false.
There is a lot more to understand about concurrency, modern CPUs, and efficiency than we can cover here. However, if you are concerned with the validity of the assertion that Node.js is good technology for writing efficient web servers, then you may want to understand more about concurrency.
Besides concurrency, there are a number of justifications given for using Node.js. Are these justifications valid? I think consistency is important. If I say X is better than some Y because of some reason J, and there is some X' that is basically equivalent to X and Y' equivalent to Y, then X' should probably be better than Y' for the same reason J. That idea is expressed in symbols below, where the long horizontal line means that the statements above logically imply the statement below the line.
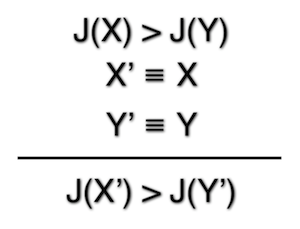
One reason given for using Node.js is that the same language, Javascript, can be used on both the client and the server. If that is true, then why shouldn't someone use GWT and use Java on both the client and server? Since the JVM works very well on the server, certainly the effort put into GWT could be seen as the equivalent of the effort put into Node.js to make a browser technology work well on the server. At the least, when you hear the "same language" justification, you should be looking for places where the same justification could be made but you don't find it convincing. If the justification isn't convincing when you substitute analogous elements, then either the justification is flawed or it is missing something that would differentiate the two situations.
Often, the same language justification for using Node.js is promoted by people who are also bragging about being polyglot programmers. Not only is knowing more than one programming language beneficial, it's basically required these days. But if knowing more than one language is offered as a positive, why is it important to use the same language on client and server? I'm not saying this argument is invalid, but rather that the justification should examined for consistency.
Another reason given for using Node.js is that there are many Javascript programmers. However, statistically, that means there are many mediocre or poor quality Javascript programmers. And if concurrent applications are so hard, do you want a lot of mediocre or poor programmers building them? Again, many Javascript programmers may be a justification for using Node.js but by itself, the justification is problematic. It's likely an extreme over-simplification. As such, it has dubious value as more than just a convenient dismissal of someone who challenges the rationale for using Node.js.
It may be that using Node.js is just more fun for many people. This is a great reason to use Node.js. However, it is not one that can be used to evaluate the technical merit of the technology. Which is fine. Recall that I'm asserting programming is a behavioral science. We should be studying and giving adequate weight to considerations that are not merely technical. Humans are using Node.js.
Finally, despite being controversial, I'm going to give some opinions about Node.js based on my experience. The point is not whether you believe me or not. These opinions should be examined critically with the objective of determining their validity using methods suggested above.
More CPU cores is the trend for the future. Typical programs have a huge amount of state. Every library loaded is program state. Running multiple processes demands duplicating the memory used by each process times the number of running processes. As long as the total memory needed to saturate the CPU cores is less than the memory available, using processes should not be a problem. However, we have seen in Ruby, at least, that it is not typically the case. Memory pressure is a constant problem. Solutions to this memory pressure like copy-on-write (CoW) friendly garbage collection are hard and not guaranteed to be that effective. If the mutable part of the heap is small then there is also very likely little shared state that would complicate simply using threads. If the mutable part is large, you get the same memory pressure over time regardless of CoW-friendly GC.
Since it is extremely unlikely that Javascript will add threads to the standard, Node.js will either be essentially single-threaded or programs will use non-standard libraries to introduce threading. This forces Node.js to use process concurrency to achieve parallelism. In this respect, I think that Node.js rejects the multi-core reality that confronts us.
In fact, Node.js is already confronting the issue of process concurrency. In Ruby, we have Passenger for managing multiple worker processes. There is now a similar system for Node.js called Cluster.
Another concern is that an entire ecosystem of libraries and tools must be built up for Node.js. Javascript was confined to the browser of a long time, and that environment is quite impoverished. In building those libraries, many mistakes that have been make in other languages will be made again. That is simply the nature of humans doing work. We make mistakes. Ruby and other languages have repeated mistakes from languages that came before them. I'm not saying that the work that must be done won't be offset by its future value. I am saying the work must be done and its value should be questioned. There is always an opportunity cost for choosing to do an activity. It is the cost of not doing another activity. In attempting to answer the question whether Node.js is better for our problem, we must consider these issues.
Concurrency is definitely a concern for practically every currently popular programming language. If you have heard that Node.js enables solutions not possible in other languages, I encourage you to look more deeply into the situation. In Ruby, I recommend checking out the Celluloid project by Tony Arcieri. The project's aim is to bring various concurrency mechanisms to Ruby. He is someone with a lot of experience and accomplishments and I'm confident his projects will advance the state of the art in Ruby and hopefully other languages as well. If you are a Clojure enthusiast, you may want to look at Carl Lerche's momentum project. Of course, there are many languages and frameworks that handle concurrency and more are under active development. Node.js is not new technology; it's merely new for Javascript.
Ultimately, the answer to, "Is Node.js better?" is not that important. People will use Node.js even if it's not the best solution to their problem. Other people will not use it even if it is great for their particular problem. Both results limit the benefits available to all of us. Further, we will continue to confront the question, "is this better than that?" If we improve our ability to answer that question, hopefully we will increase the benefit to us all.
Slides for "Nikita - The Ruby Secret Agent"
ED. I've converted the slides to PDF and uploaded them to speakerdeck.com.

ED. The except from the 2011 OSCON Twitter talk is below.
A VM by any other name
With the recent switch away from the spaghetti stack execution model, Rubinius has also acquired native threads. A big part of understanding something is syncing up our mental model with reality. If you’ve ever tried to explain what an OS is to your mom, you know that can be a challenge. So let’s peel back a few layers and see where these native thread critters fit into Rubinius.
Rubinius is an implementation of the Ruby programming language. One of the bigger components is the virtual machine. But what is that? Unfortunately, virtual machine is a label for a category of software (and maybe hardware) that, well, does a bunch of different things. Virtual machines are often thought of as virtual computers or virtual CPUs. The problem with trying to equate two things is that you look at the one you know about and try to understand the one you do not by looking for analogous structures. Therein lie the seeds of misunderstanding. Since Rubinius has this vm/ directory, we’ve got to try to nail some of this gelatin to the wall.
Thinking about threads running inside a physical computer, you might visualize the relationship something like the following Ruby-ish pseudo code. As the program starts up, it creates a virtual machine.
1 def main
2 vm = VM.new
3 # do some setup
4 vm.run
5 end
Sometime later in the program, you add a new thread, which might be implemented something like this.
1 def Thread.new
2 thr = VM.threads.create
3 # ...
4 return thr
5 end
You might imagine the VM instance having a Scheduler component that would supervise the threads and arrange for running them on one or more processors or cores. In this model, the VM is really like a virtual computer in which all execution is occurring. In other words, the VM is composed of multiple threads of execution.
The point of this mental exercise is to expose the tacit assumptions we might have about our mapping between a real computer and the virtual machine. Now let’s delve into Rubinius.
The main function is located in vm/drivers/cli.cpp. The first thing it does is create an instance of Environment, which is composed of an instance of VMManager, SharedState, and VM. In the Environment constructor, the command line is parsed for configuration options. Then the manager creates a new shared state. The shared state creates a vm. And finally the vm is initialized. During initialization, the ObjectMemory is created. The object memory in turn is composed of garbage collected heaps for the young and mature generations.
Back in main, a platform-specific configuration file is loaded, the “vm” is booted, the command line is loaded into ARGV, the kernel is loaded (i.e. the compiled versions of the files located in the kernel/ directory), the preemption and signal threads are started, and finally the compiled version of kernel/loader.rb is run, which will process the command line arguments, run scripts, start IRB, etc. When your script, IRB, -e command, etc. finish running, loader.rb finishes, main finishes, resources are cleaned up, and finally the process exits.
Whew. The point of this whirlwind tour is to illustrate that VM is a rather fuzzy concept, even though we have a class named VM. Now let’s take a look at how threads fit in.
Rubinius has a 1:1 native thread model. In other words, each time you do Thread.new in your Ruby code, the instance returned maps to a single native thread. In fact, let’s look at the code for Thread.new in kernel/common/thread.rb.
1 class Thread
2 def self.new(*args, &block)
3 thr = allocate
4 thr.initialize *args, &block
5 thr.fork
6
7 return thr
8 end
9 end
The calls to allocate and fork are implemented as primitives in C++ code. They are short, so we’ll take a look at them, too.
1 Thread* Thread::allocate(STATE) {
2 VM* vm = state->shared.new_vm();
3 Thread* thread = Thread::create(state, vm);
4
5 return thread;
6 }
7
8 Object* Thread::fork(STATE) {
9 state->interrupts.enable_preempt = true;
10
11 native_thread_ = new NativeThread(vm);
12
13 // Let it run.
14 native_thread_->run();
15 return Qnil;
16 }
The call to allocate creates a new instance of VM as thread local data. The call to fork creates the new native thread. The call to native_thread_->run() will eventually call the __run__ method in kernel/common/thread.rb. Something to note about this snippet of C++ code is the nice consistency between the primitives and the Ruby code that calls them.
We’ve encountered the VM class in two contexts: 1) when starting up the Rubinius process, and 2) when creating a new Thread. We can consider the VM instance to be an abstraction of the state of a single thread of execution, and in fact, state is the name most often given to an instance of VM in the Rubinius source.
As we’ve seen, Rubinius as a running process is composed of various abstractions, including the Environment, SharedState, NativeThread, and VM to name a few. While it is accurate to call Rubinius a virtual machine, it is apparent that concept can cover a fair bit of complexity. But breaking it into parts makes it fairly easy to understand. Let us know what things you’d like to understand better. We have the doc/ directory in the source that we’re (slowly) building out. If you’re interested in contributing, docs would be a great way to help everyone.
Come to the Open Source Bridge conference
If you live in or would like to visit beautiful Portland, OR, consider signing up for the Open Source Bridge conference. I will (probably) be giving a talk on RubySpec and Rubinius 1.0. There’s lots of interesting folks giving great talks. This is an opportunity to hear how people are developing the open-source community.
Hope to see you there!
When describe'ing it ain't enough
One of the things I like about the RSpec syntax is that it packs a lot of information into a few concise, consistent constructs. It’s relatively easy to read through a spec file and pick out what I am looking for. The use of blocks both enable flexible execution strategies and provide simple containment boundaries.
Perhaps the most valuable aspect, though, is the ability to extend the RSpec syntax constructs easily and consistently. No need to grow a third arm here. In Rubinius, we recently encountered a situation needing some extra sauce when fixing our compiler specs.
A compiler can be thought of as something that chews up data in one form and spits it out in another, equivalent, form. Typically, these transformations from one form to another happen in a particular order. And there may be several of them from the very beginning to the very end of the compilation process.
To write specs for such a process, it would be nice to focus just on the forms of the data (that’s what we care about) with as little noise as possible about how they got there. Here’s what we have in Rubinius:
1 describe "An And node" do
2 relates "(a and b)" do
3 parse do
4 [:and, [:call, nil, :a, [:arglist]], [:call, nil, :b, [:arglist]]]
5 end
6
7 compile do |g|
8 g.push :self
9 g.send :a, 0, true
10 g.dup
11
12 lhs_true = g.new_label
13 g.gif lhs_true
14
15 g.pop
16 g.push :self
17 g.send :b, 0, true
18
19 lhs_true.set!
20 end
21 end
22 end
The relates block introduces the Ruby source code and contains the blocks that show various intermediate forms. A single word like parse and compile encapsulates the process of generating that particular form, as well as concisely documenting the specs.
The format is sufficiently flexible to allow for other forms. For instance, ast for generating an AST directly from the parse tree rather than using the sexp as an intermediate form. Or llvm to emit LLVM IR directly from our compiler.
Another interesting aspect of this, it was possible with only a few custom extensions to MSpec. Recently, I had added custom options to the MSpec runner scripts to enable such things as our --gc-stats. I didn’t know how easy it would be to add something more extensive. Turns out it was pretty easy. You can check out the source in our spec/custom directory.
What is RubySpec?
According to the folks over at http://rubyspec.org, “RubySpec is a project to write a complete, executable specification for the Ruby programming language.” As with any sufficiently concise summary, there’s some opportunity for misunderstanding here, so let’s explore a few aspects of this definition.
Since this post is a bit long, here’s a summary:
- There is one standard definition of Ruby.
- RubySpec benefits the whole Ruby ecosystem.
- RubySpec does not guarantee that program A will run on implementation B.
- RubySpec includes only specs for the correct behavior when bugs are discovered in MRI.
- Help your favorite Ruby implementation by contributing to RubySpec.
First, what does it mean to be “the Ruby programming language”? The answer to this question used to be a little simpler before Ruby 1.9. Originally, there was the single Ruby implementation that Matz and friends built, referred to as MRI (Matz’s Ruby Interpreter). Now there is also RubyVM or KRI (Koichi’s Ruby Implementation) or simply Ruby 1.9. Either way, MRI 1.8.x and [KM]RI 1.9.x are the standard or reference implementations for Ruby. Everyone else is making an alternative implementation that either complies with the standard or deviates from it.
This is the way RubySpec is written. I realize that it’s possible to consider “the Ruby programming language” to be an abstract thing and all the Ruby projects as merely more or less equal attempts to implement the language. I won’t try to convince you that either way of viewing this is more or less correct. I just want to be clear about the way RubySpec views it.
At the time I began writing what eventually became RubySpec, the only Ruby implementation in wide-spread use was MRI. My biggest concern when getting involved with Rubinius was that the project would be consistent with Ruby the way Matz defines it and not cause fragmentation of the language. My reason was quite selfish. I loved programming in Ruby and I wanted to see the language thrive.
So, RubySpec’s over-arching value proposition is a single, comprehensive definition of the Ruby programming language. To see if the value proposition is actually universal, let’s examine the three categories of people involved with Ruby: consumers, programmers, and implementers.
I define consumers as anyone who depends on a product or service written in Ruby. Consumers may use these products and services directly, or they may own or work for companies that provide them, or they may use products and services that are themselves supported by software written in Ruby. Consumers are the biggest part of the Ruby ecosystem.
Interacting closely with the consumers are programmers, the men and women who write software or frameworks in Ruby. In fact, the same folks may be both consumers and programmers.
The implementers are the people writing Ruby implementations for the programmers and consumers. They want to experiment with ways to better support programmers without worrying that they are breaking their programs in unknown ways. Again, the implementers may be programmers or consumers themselves.
If you’ve ever used a proprietary implementation of a programming language or know what vendor lock-in means, then I am preaching to the choir. If not, then consider that system requirements change, hardware changes, services change, customers change, development teams change, everything changes.
Consumers want assurance that the products and services on which they depend will remain available and will grow with their needs. Programmers want assurance that they will be able to meet their customers’ needs. Implementers want to provide programmers the ability to do so. A single, consistent Ruby language really is a win-win-win situation.
With everything seeming so sunny, one may be tempted to think: “If implementation A and B perform the same on RubySpec, then a program running on A now should run just fine on B.” Unfortunately, it is not quite that simple. Just as a program may not run on both OS X and Linux simply because MRI runs on both. Once in a while, RubySpec finds bugs in MRI, though not that often considering the tens of thousands of expectations. Since a lot of the code in MRI has been around for years, this illustrates that even running thousands of programs (RubySpec is just another program) is no guarantee that there are not bugs lurking around the corner.
What can tell you whether a program will (likely) run on both A and B is the program’s own test suite. In this regard, the program’s test suite and RubySpec are complementary. If the tests discover something that RubySpec did not, it is an opportunity to enhance RubySpec. If running on another implementation expose issues not uncovered by the program’s tests, it is an opportunity to enhance the tests.
Ruby versioning is complex affair and another area where possible misunderstandings exist about RubySpec. It seems pretty simple that Ruby 1.8 and Ruby 1.9 are different. But then there is 1.8.7, which is like 1.8.6 and 1.9. And there may be 1.8.8, which will likely be different than 1.8.6 and 1.8.7 and 1.9. It is dizzying. RubySpec handles the different versions by using the ruby_version_is guard. (Read the guard documentation for full details.)
Generally, the version guards work fine. Each implementation provides the RUBY_VERSION constant and based on its value, the guards permit the correct specs to run. Some have assumed this means RubySpec will tell you that alternate implementation A is just like MRI version X.Y.Z “bugs and all” because A says it is version X.Y.Z.
The principles RubySpec strives for are correctness, clarity, and consistency. There is no way to provide clear and consistent results if RubySpec included specs for the wrong behavior as well as specs for the correct behavior. Either clarity or consistency suffer, badly. Matz is the one who ultimately determines whether a behavior is a bug or not. RubySpec simply includes specs for only correct behaviors.
These are some of the factors that complicate this issue:
- There is no definition of what is a bug. It may be a segfault, an incorrect value computed, a frozen state not set or respected, the wrong exception class raised. The list is endless and impossible to consistently categorize.
- All implementations, including MRI, have their own release processes and schedules.
- RubySpec is a social as well as technical project. An aspect of the value-added proposition for any given implementation is the quality that they provide. There is no way the alternative implementations will consistently agree to defer fixing bugs until MRI releases a fix. Rather than supporting cherry-picking which bugs to fix, RubySpec only includes correct specs.
- Bugs discovered by RubySpec in MRI are quite rare.
Finally, contributing to RubySpec is one of the lowest barriers-to-entry means of supporting your favorite Ruby implementation and the Ruby ecosystem as a whole.
Consider what the view looks like from the outside: Ruby has a vibrant community of implementations meeting consumers’ and programmers’ needs on virtually every significant platform, including on Java, .NET, Mac (Obj-C), and semi-platform-agnostic implementations like MRI and Rubinius. Internally, it means that Ruby programmers can focus more on writing their programs using the best tools for the job, confident that if requirements change they can move to a different platform with ease and confidence.
Check out the RubySpec docs if you are interested in helping out.
Boxers or Briefs? -- Neither?!
The emperor is wearing clothes and everything looks hunky-dory and sane on the outside. Usually, that’s a good thing. For instance, when running RubySpec on a released version of MRI, it’s good to know that things are behaving as expected and all known issues are accounted for. In other words, you won’t see any failures unless a spec is broken or a new spec has uncovered a bug.
$ mspec library/stringio/reopen_spec.rb ruby 1.8.6 (2008-03-03 patchlevel 114) [universal-darwin9.0] ........................ Finished in 0.021797 seconds 1 file, 24 examples, 59 expectations, 0 failures, 0 errors
While the above can be reassuring, it may not tell the whole story. RubySpec uses guards to control which specs are run. This enables the specs to accommodate differences in behavior due to varying platforms, versions, implementations, and bugs.
I’ve added a couple features to MSpec to enable discrete and not-so-discrete peeks under the robes, as it were. The first of these is akin to just yanking down the trousers. By passing the --no-ruby_bug option, all ruby_bug guards are disabled and the guarded specs are run.
$ mspec --no-ruby_bug library/stringio/reopen_spec.rb ruby 1.8.6 (2008-03-03 patchlevel 114) [universal-darwin9.0] ............FF.....FF.....FF...... 1) StringIO#reopen when passed [Object, Object] resets self's position to 0 FAILED Expected 5 to have same value and type as 0 ./library/stringio/reopen_spec.rb:117 ./library/stringio/reopen_spec.rb:110:in `all?' ./library/stringio/reopen_spec.rb:61 ---- snip ---- Finished in 0.022210 seconds 1 file, 34 examples, 76 expectations, 6 failures, 0 errors
If you cringe a little when blasted by a bunch of failures, don’t worry, So do I. For a more subtle examination, there is also the ability to run the specs and note which specs would have run but did not due to guards.
$ mspec --report library/stringio/reopen_spec.rb ruby 1.8.6 (2008-03-03 patchlevel 114) [universal-darwin9.0] ........................ Finished in 0.009809 seconds 1 file, 24 examples, 59 expectations, 0 failures, 0 errors, 10 guards 4 specs omitted by guard: ruby_bug #, 1.8.6.114: StringIO#reopen reopens a stream when given a String argument StringIO#reopen reopens a stream in append mode when flagged as such StringIO#reopen reopens and truncate when reopened in write mode StringIO#reopen truncates the given string, not a copy 6 specs omitted by guard: ruby_bug #, 1.8.7: StringIO#reopen when passed [Object, Object] resets self's position to 0 StringIO#reopen when passed [Object, Object] resets self's line number to 0 StringIO#reopen when passed [String] resets self's position to 0 StringIO#reopen when passed [String] resets self's line number to 0 StringIO#reopen when passed no arguments resets self's position to 0 StringIO#reopen when passed no arguments resets self's line number to 0
The guards are reported only if they have altered how the specs were run. Since the ruby_bug guard can only prevent specs from running on the standard implementation, MRI, those guards are not reported when running under JRuby, for instance.
$ mspec -t jruby --report library/stringio/reopen_spec.rb jruby 1.2.0RC1 (ruby 1.8.6 patchlevel 287) (2009-02-26 rev 9326) [i386-java] .................................. Finished in 0.257000 seconds 1 file, 34 examples, 76 expectations, 0 failures, 0 errors, 0 guards
So, if you are wondering what is going on with some specs for a particular library, you can get a quick peek using the --report option before digging into the spec files. There is also a --report-on GUARD option that allows you to narrow the focus of your peeking.
Warning: Includes Known Bugs
UPDATE: In further discussions with Jim Deville of IronRuby it appears that there may be a legal issue preventing IronRuby devs from patching Ruby code themselves. However it may be possible for IronRuby to use a commonly maintained and patched version of the standard library.
Reviewing the logs and considering this was Shri’s first major discussion in the IRC channel, I unfortunately grouped him in with Charles’ intolerable behavior and personal attacks which have occurred on a number of occasions in #rubyspec and #rubinius. My apologies to Shri. The struck out text below remains merely for historical accuracy.
UPDATE: Charles response to this post wasn’t exactly positive, but I think it’s fair to have this discussion in public: http://pastie.org/400493 Also, please note that I’ve struck out Shri’s name below as I may have misunderstood him in the earlier discussion.
You, the trusting consumer, would probably like to receive such cautionary advertisement were you to use a product that did, in fact, ship to you code that includes known bugs. And not just known bugs, but known bugs that have fixes for them.
You would like to know this, right? I mean, I’m not just some hard-headed asshole that thinks there’s something a bit whack here, am I? Please, do tell me.
Well, as luck would have it, you can also tell this to Charles Oliver Nutter of JRuby and Shri Borde of IronRuby.
Here’s the drama: There’s this project RubySpec. You may have heard of it. It attempts to describe the behavior of the Ruby programming language. All the alternative Ruby implementations use the RubySpec project to attempt to show that they are “Ruby”.
All the alternative implementations also choose to ship some version or other of the Ruby standard library. At least the parts written in Ruby. Makes sense, since they all implement the Ruby programming language.
As is the case with all software, from time to time bugs are discovered in Ruby. Usually, these are fixed soon after they are discovered and the fix is committed to the trunk version of MRI (Matz’s Ruby Implementation). Eventually, trunk becomes another stable release with a particular patchlevel.
The RubySpecs deal with this situation with a ruby_bug guard. You can read the details of RubySpec guards. This particular guard has two functions:
- It prevents the guarded spec from executing on any version of MRI less than or equal to the version specified in the guard. This is because MRI cannot re-release a particular patchlevel after it has been released. And the bugs are discovered after a release.
- It documents the spec, which shows what the correct behavior should be.
A key feature of the ruby_bug guard is that it does not prevent the spec from running on any alternative implementation. That is because every alternative implementation is expected to have the correct behavior. Additionally, these guards are only added after Matz or ruby-core has stated that the behavior at issue is a bug and the behavior of the spec is the correct behavior.
Now here is the rub, Charles does not want to manage patching the Ruby standard library that he ships with JRuby with the patches that already exist for known bugs. He wants to ship whatever version MRI has most recently released. Further, when you run the RubySpecs with JRuby, he wants to MASK those bugs because he doesn’t think it’s fair that JRuby fails a spec which shows a known bug in the Ruby standard library for which patches are available.
That’s Charles choice of strategies for managing JRuby packaging. I’m strongly of the opinion that you, the user, would like to know that. Charles apparently disagrees.
In fact, he disagrees so vehemently that he takes to calling me names in the #rubyspec IRC channel because I refuse to change the fact that the ruby_bug guard will not silently mask spec failures on JRuby or any other alternative implementation. Aside from being immature, I think there is a real problem with this. Don’t you?
Charlie will argue that it is simply impossible to ship the trunk version of Ruby standard library because it is an unknown quantity? However, the best defense against bugs in the Ruby standard library is better specs. And we’re talking about specs here that show the bugs and for which patches exist. Furthermore, there are actually relatively few bugs noted in the specs and most of those are in older versions of Ruby, not the current stable release.
So, here’s my question to you: Would you like to know that JRuby and possibly IronRuby ship you code that contains know bugs for which patches exist? Would you also like to know that Charles wants you to run RubySpec on JRuby and not know there is a bug?
